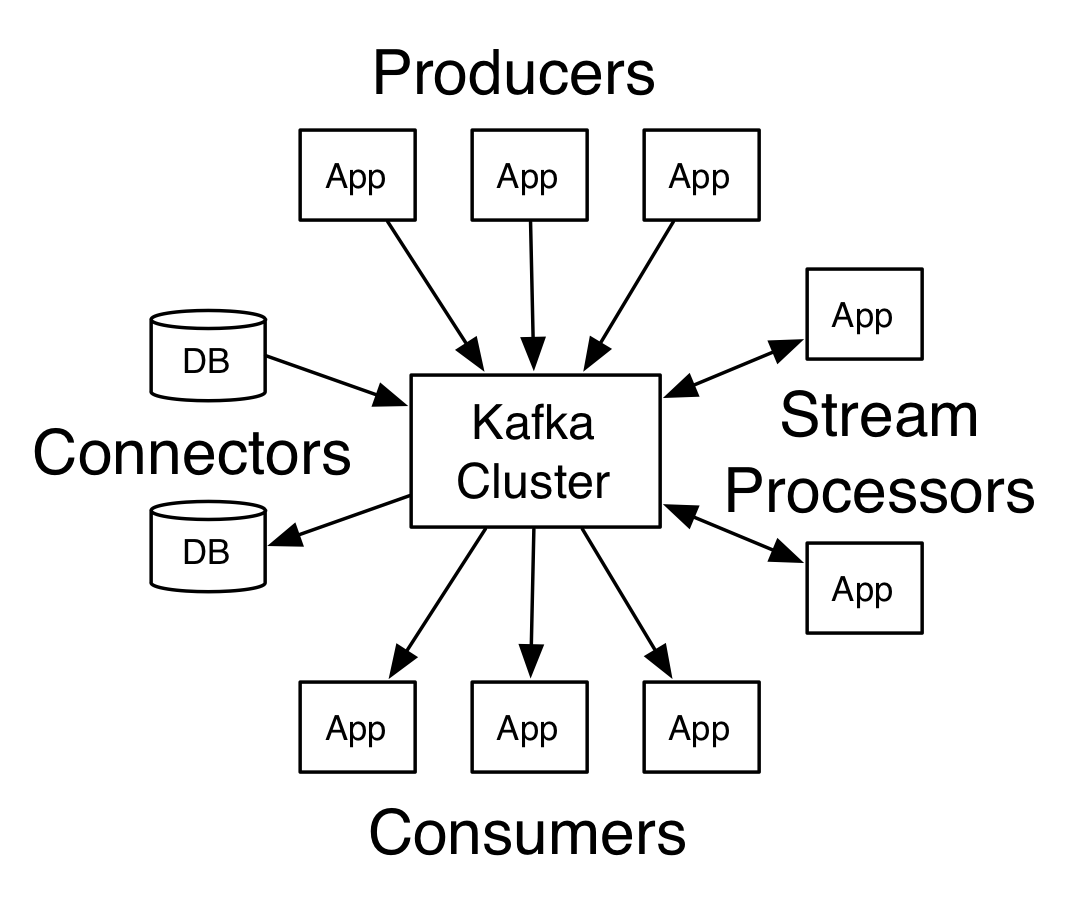
历史
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
特性
核心特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展。
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
- 高并发:支持数千个客户端同时读写。
核心API
- Producer API
- Consumer API
- Streams API
- Connector API
Topic 和 Log
Topic类似于一个分类或feed名称,其下会发布很多记录供多个消费者调用。对每个topic,kafka集群维护一个分区记录(Partition log)。
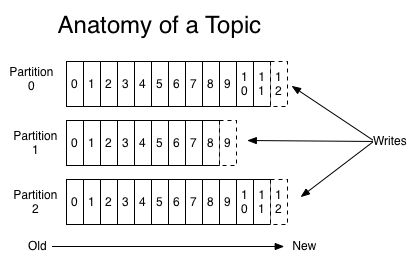
每个分区是一个固定排序的、不可变的记录序列,每条记录都有一个对应的记录号,这里称为offset。不管数据是否被消费过,Kafka都会将数据持久化,只有超过保留周期的数据会被清理。
1 | Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem. |
在每个consumer的日志中会记录当前消费的位置 offset,默认情况下消费是从后往前依次递增的,消费者也可以自己决定消费的顺序,通过控制 offset 可以重复消费以前消费过的内容。
分区的作用?分区可以有1个或者多个,分为leader和follwers。leader负责处理所有的读写请求,其他的则负责复制。如果leader发生故障,则其中一个follwer被选为leader。
Producer
两种模型的对比
传统的消息中间价分为两种,一种是队列模式,一种是发布-订阅模式。
传统的队列模式优点在于允许将数据处理的进程横向扩展为多个,提高数据的处理速度。缺点是不能支持多个订阅者,一旦数据被读取后就没有了。
发布-订阅模式的优点在于允许将数据广播给多个订阅者,但是订阅者没办法横向扩展。
Kafka提出的consumer group的概念结合了两者的优点。当队列模式用时,允许处理进程横向扩展。当发布-订阅模式用时,允许广播给多个consumer group。Kafka模型的优点在于,你无需选择,就可以同时拥有队列模式和发布-订阅模式的特点。同时,Kafka对于消息顺序性的保证也比传统的消息系统强很多。
传统的队列在服务端保存消息的顺序,当多个消费者调用时,服务端按顺序将消息发送给消费者。但是因为延时的影响,消息到达消费端时可能不是按照保存的顺序到达的。通常为了解决这个问题,会采用排他性消费者的模式,即一次只允许一个消费者读取数据。但是这样就不能够满足并发的需求了。
通过在Topic下设置partition的方法,Kafka能够同时满足并发的需求,并保证消息的时序性。这就有个限制,即consumber group中消费者的数量,不能超过partition的数量。
Kafka还是一个好的存储系统
流式消息处理
配置
| 字段 | 选项 | 含义 | 备注 |
|---|---|---|---|
| log.cleanup.policy | delete和compact,默认是delete | 清理策略 | segment是数据清理的基本单元,正在使用的segment不会被清理 |
| log.cleaner.enable | true | ||
| log.retention.bytes | |||
| log.retention.hours | |||
| log.retention.minutes | |||
| log.retention.ms |
config/server.properties
常用操作
查看Kafka集群Topic
1 | $ bin/kafka-topics.sh --list --zookeeper 192.168.187.146:2181 |
查看Kafka集群Topic描述信息
1 | $ bin/kafka-topics.sh --describe --zookeeper 192.168.187.146:2181 --topic topic_name |
能够看到Topic的partition数量、replica因子以及每个partition的leader、replica信息。
查看 consumer group 列表
区分新版、老版consumer有不同的参数。
老版的查看方式。
1 | $ bin/kafka-consumer-groups.sh --new-consumer --bootstrap-server 127.0.0.1:9292 --list |
新版的查看方式。
获取某个Topic内容(消费内容)
1 | $ bin/kafka-console-consumer.sh --zookeeper node01:2181 --topic t_cdr --from-beginning |
参考资料:
- Kafka Introduction
- 漫游Kafka之过期数据清理
- [Kafka] - Kafka基本操作命令
- Kafka的2种日志清理策略感受一下
- Kafka查看topic、consumer group状态命令

用心体验、认真记录,欢迎关注大江小浪的技术人生!