Logstash作为一个数据处理管道,提供了丰富的插件,能够从不同数据源获取用户数据,进行处理后发送给各种各样的后台。这中间,最关键的就是要对数据的类型就行定义或映射。
本文讨论的 ELK 版本为 5.5.1。
为什么要定义数据
Elastisearch不仅是一个强大的全文检索引擎,它还能够对一些数据类型进行实时的统计运算,相关的结果可以通过Kibana的图表展现出来。如果数据类型没有正确的定义,那么Elasticsearch就无法进行运算了,因此,虽然数据类型的定义需要花一点时间,但你会收到意想不到的效果。
JSON、字符串和数字
所有送往Elasticsearch的数据都要求是JSON格式,Logstash所做的就是如何将你的数据转换为JSON格式。ElasticSearch会帮我们自动的判断传入的数据类型,这么做当然极大的方便了用户,但也带来了一些问题。
Elastic中的一些数据类型:text、keyword、date、long、double、boolean、ip、object、nested、geo_point等。不同的类型有不同的用途,如果你需要全文检索,那应该使用text类型,如果你需要统计汇总那应该选择数据或者keyword类型。感谢动态映射 Dynamic Mapping 的存在,在向ES送数的时候我们不需要事先定义映射关系,ES会对新增的字段自动进行映射。但是你比Elasticsearch更加熟悉你的数据,因此可能需要自己进行显示定义 Explicit Mapping 映射关系。例如IP字段,默认是解析成字符串,如果映射为IP类型,我们就可以在后续的查询中按照IP段进行查询,对工作是很有帮助的。我们可以在创建索引时定义,也可以在索引创建后定义映射关系。
对于已经存在的数据,无法更新映射关系。更新映射关系意味着我们必须重建索引。
先来看下面这个JSON文档。
1 | { |
这里有五个字段:@timestamp,@version,count,average,host。其中 @timestamp 和 host 是字符串,count、average 是数字,@version比较特殊,它的值是数字,但是因为放在双引号中,所以作为字符串来对待。
尝试把数据送入到 Elasticsearch 中,首先创建一个测试的索引:
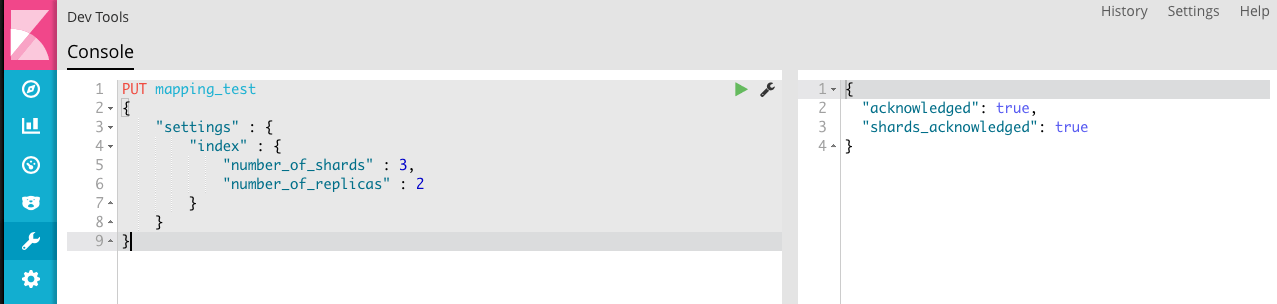
将数据存入索引
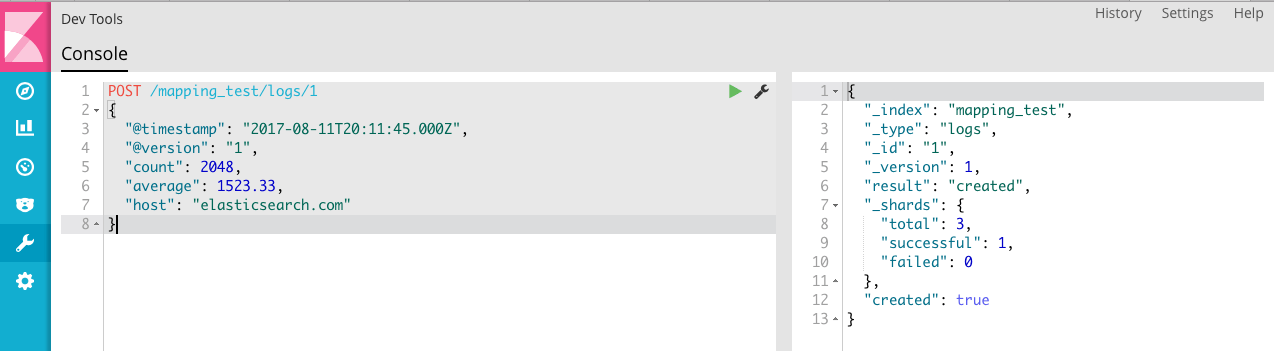
查看数据映射的情况
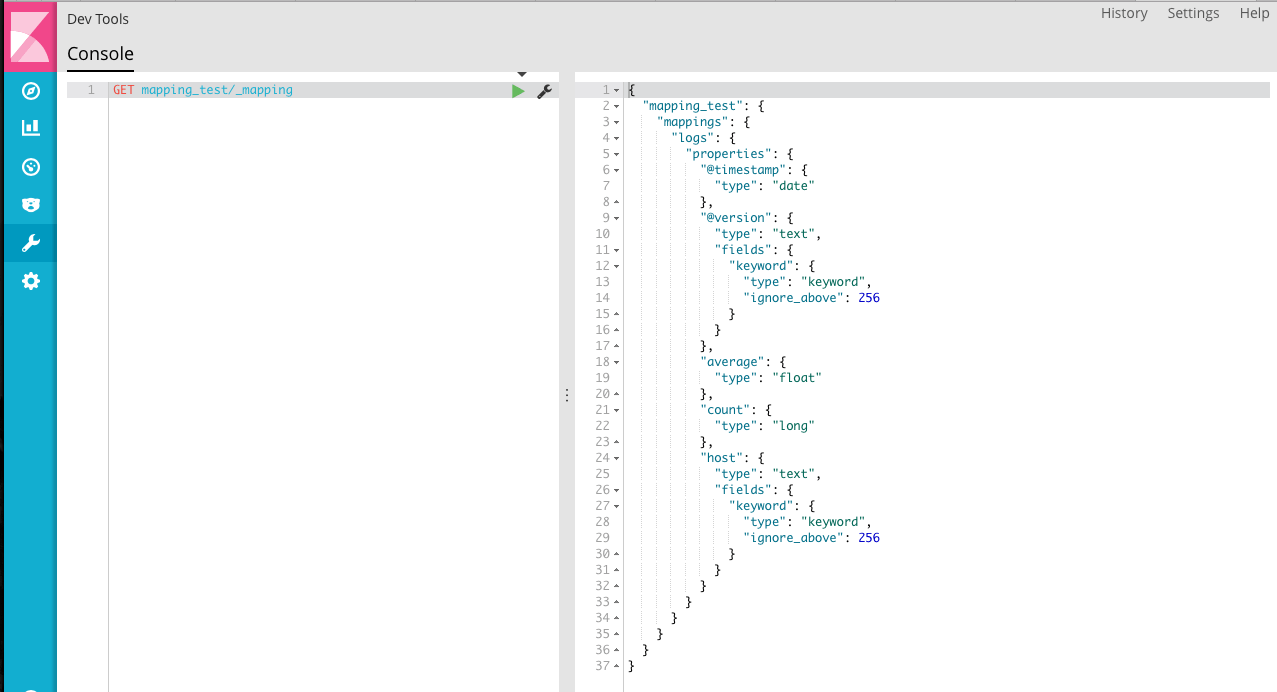
根据结果可知,在没有明确定义数据类型的情况下,Elasticsearch会自动判断数据的类型,因此 @timestamp、@version、host都被映射为 text ,average、count 被映射为数字。
在Logstash中定义数据类型映射
Logstash提供了 grok 和 mutate 两个插件来进行数值数据的转换。
grok
grok 目前是解析非结构化的日志数据最好的插件。特别适合处理syslog、apache或其他web服务器、mysql等为了阅读而输出的信息类日志。
grok 的基本用法如下:%{SYNTAX:SEMANTIC},SYNTAX是grok提供的样式Pattern的名称,grok提供了120多种Pattern,SEMANTIC是你给匹配内容的名称(标志符)。因为grok实际上是正则匹配,因此任何输出都默认转换为字符类型,如果你需要数据类型的转换,则使用下面这种格式
1 | %{NUMBER:SEMANTIC:int} |
目前,类型转换仅支持 int 和 float 两种类型。
如果将带小数的数字转换为 int 类型,会将小数后的数字丢弃。
mutate
mutate 为用户提供了处理Logstash event数据的多种手段。允许我们移除字段、重命名字段、替换字段、修改字段等操作。
1 | mutate { |
使用模版进行字段映射
Elasticsearch中通过模板来存放索引字段的映射关系,logstash可以在配置文件中指定模板文件来实现自定义映射关系。
查询 Elasticsearch 中的模板,系统自带了 logstash-* 的模板。
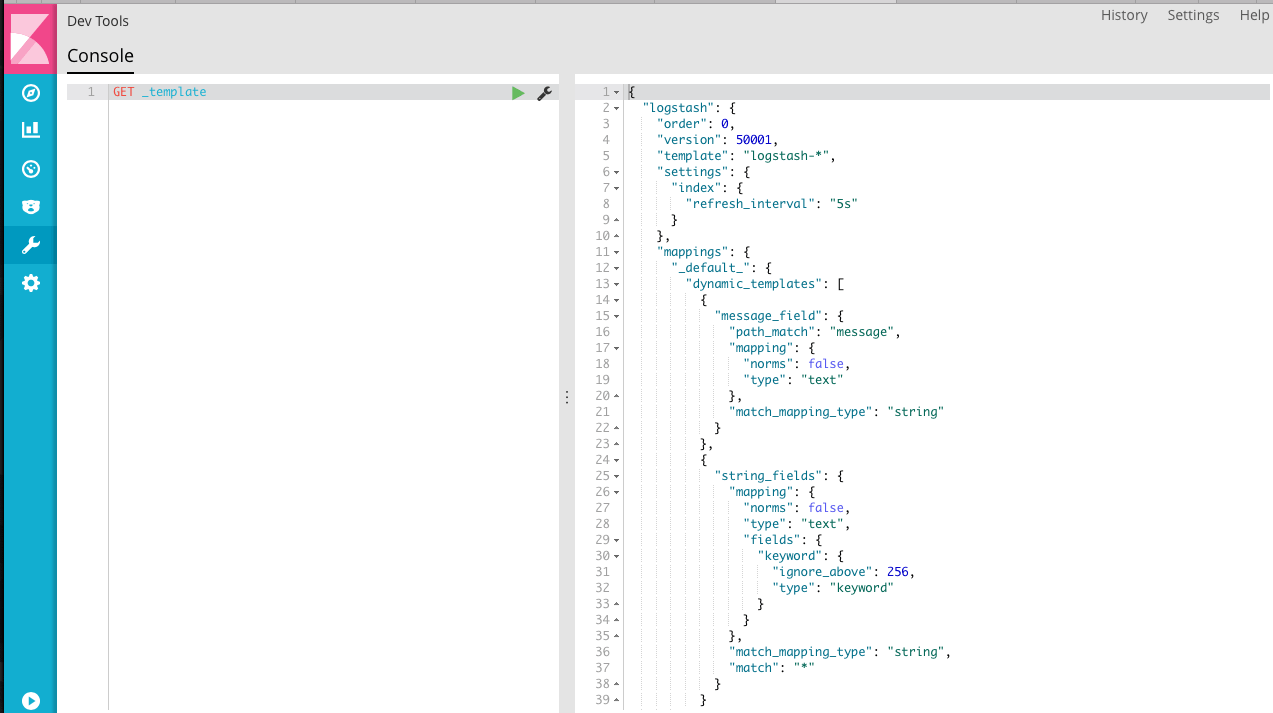
我们用实际的例子来看一下映射和模板是如何起作用的。
1、首先创建一个 logstash 配置文件,通过 filebeat 读取 combined 格式的 apache 访问日志。
配置文件名为 filebeat.conf 位于 logstash 文件夹内。filebeat的配置比较简单,可以参考我的上一篇文章Filebeat+Logstash+ElasticSearch+Kibana搭建Apache访问日志解析平台
1 | input { |
第一次数据导入的时候,我们先不使用模板,看看 es 如何默认映射数据,启动elk环境,进行数据导入。
1 | [maserati@iZ627x15h6pZ logstash-5.5.1]$ ../elasticsearch-5.5.1/bin/elasticsearch |
数据导入完成后,看一下索引的情况
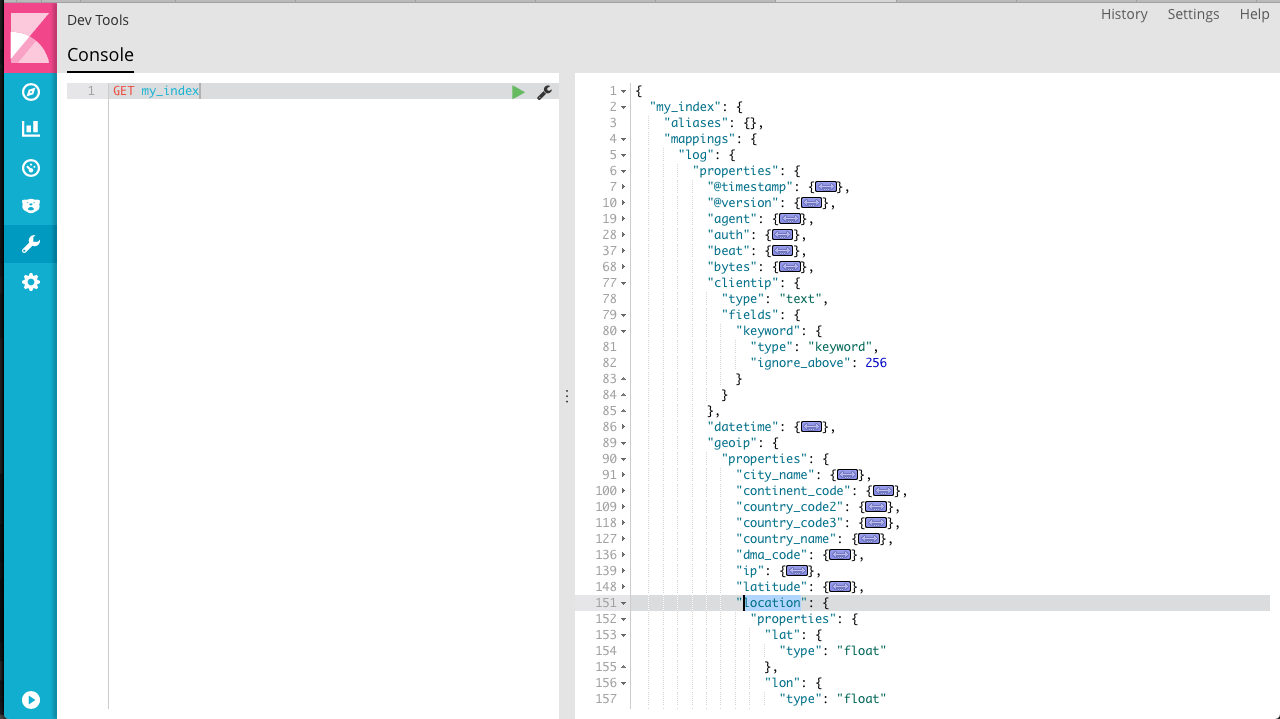
因为从log导入的数据,所以mapping中给映射规则起名为log,对应的是 document_type,可以看到clientip和 geoip.location 分别解析成了文本和数值。其他大部分内容都映射为 text 。这种不需要我们定义映射规则的处理方式非常方便,但有时候我们更需要精确的映射。
看一下ES映射模板,只有logstash命名的模板,因为名称不匹配,所以没有应用这里的映射规则。
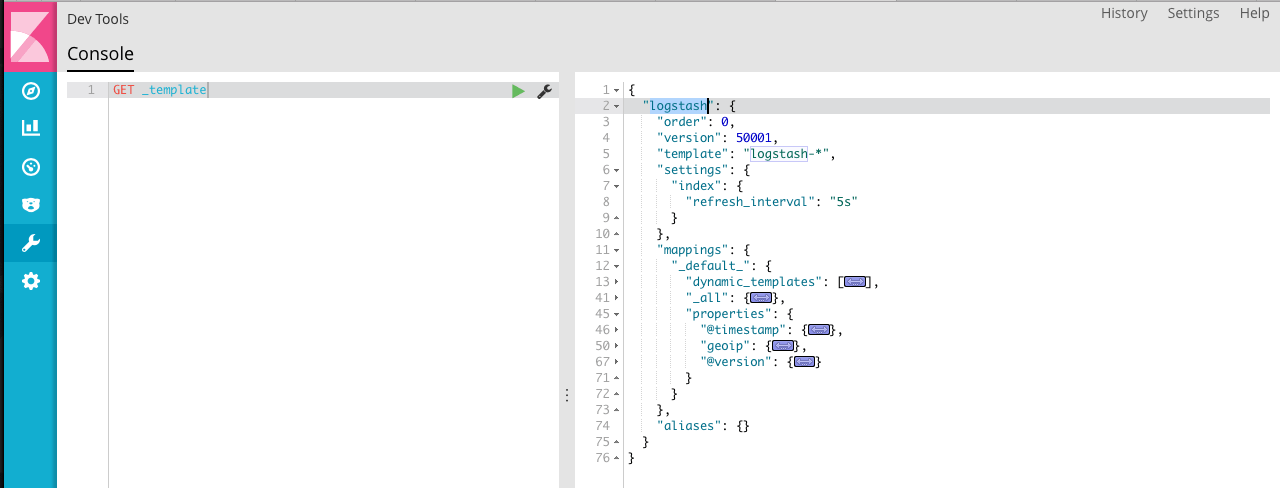
这里可以注意到模板文件和索引中的映射关系稍有不同,没关系,我们把 my_index 的映射关系拷贝下来,存为 filebeat-template.json ,这里贴一下一个删减版的 模板文件。
1 | { |
我们可以通过命令行收工把模板上传到 elasticsearch ,也可以通过 logstash 配置文件指定。
1 | curl -XPUT http://localhost:9200/_template/my_index_template?pretty -d @filebeat-template.json |
我的例子中,我们只需要把 filebeat.conf 中的注释打开即可。然后删除索引,我们对索引重建一下。
看一下索引,可以看到模板中定义的规则已经在里面了。
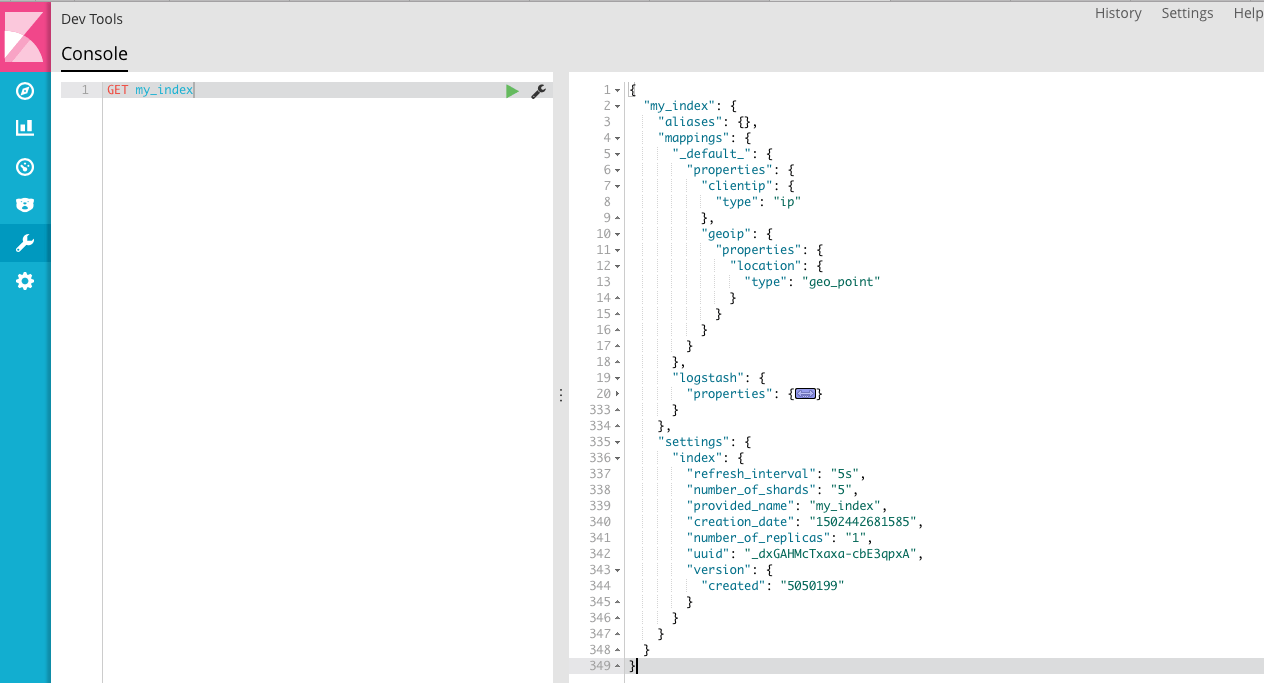
看一下索引字段,看到 clientip 已经定义成 ip 类型了。
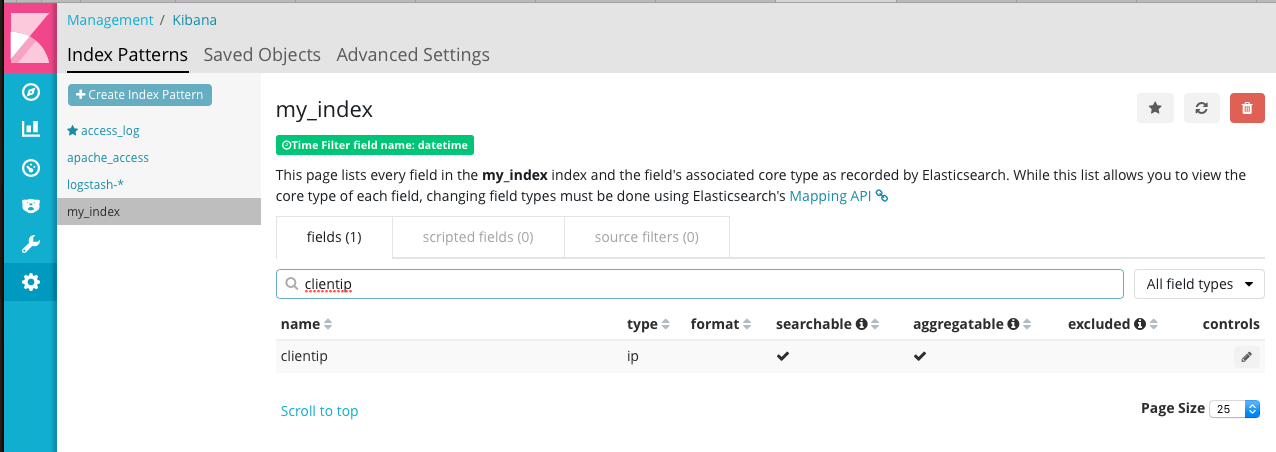
同样,geoip.location映射成 geo_point 类型。
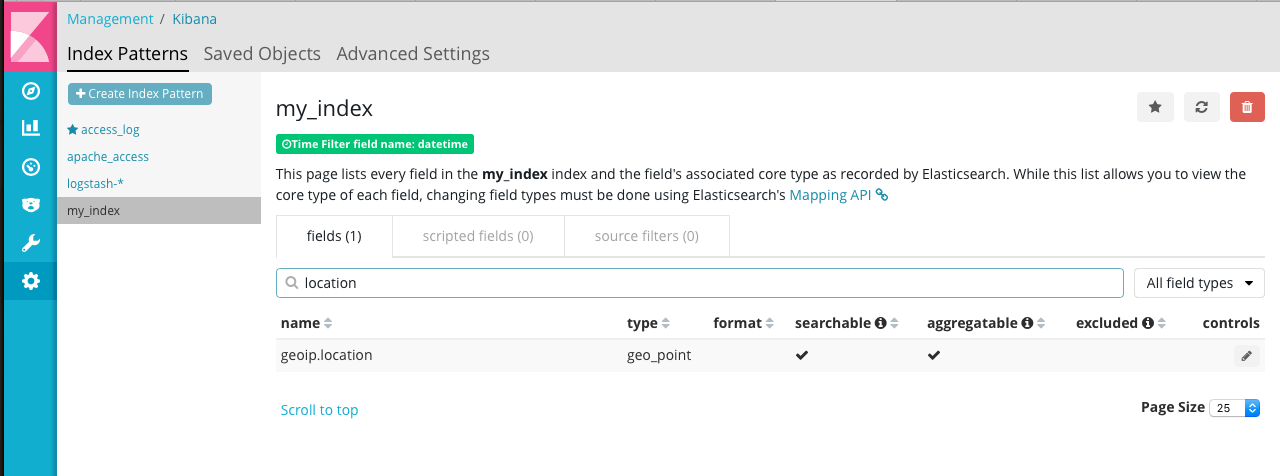
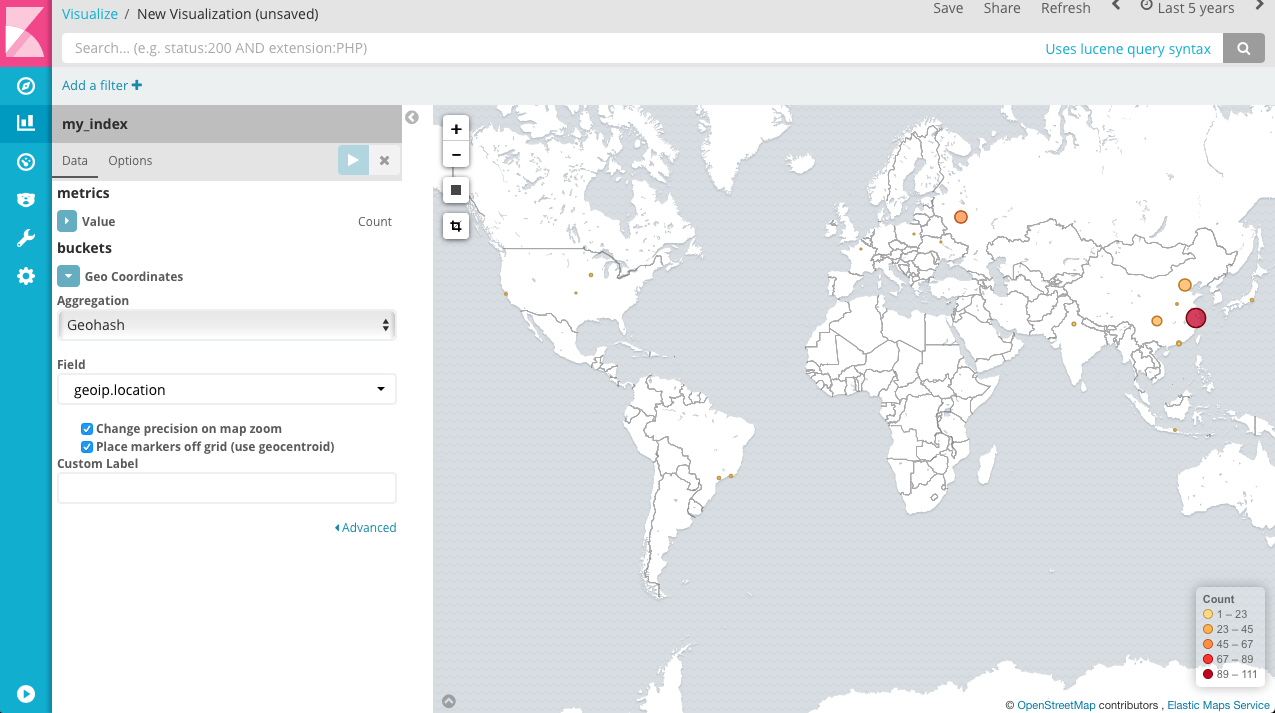
这样我们就可以做访客地图了。
这时,再看一下 template 的情况。
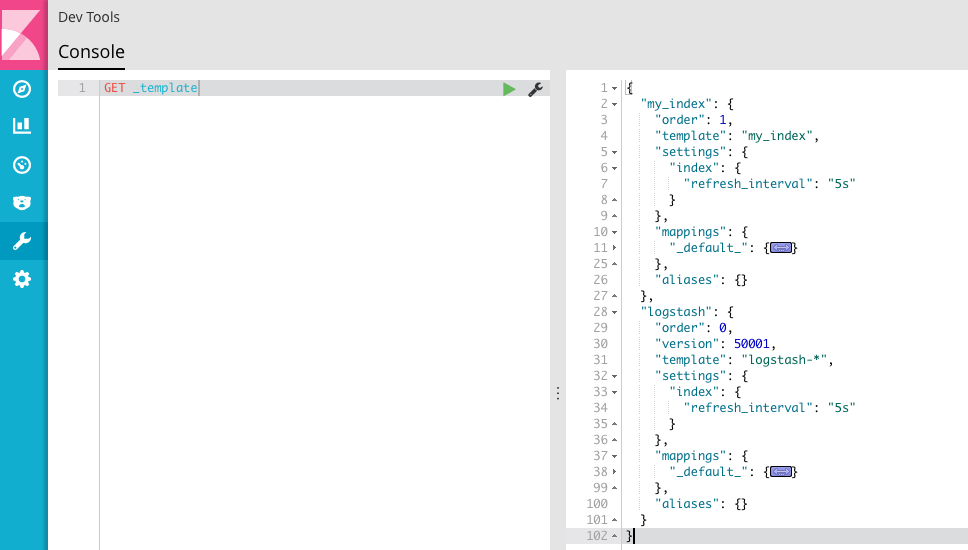
可以看到,除了默认的模板,新增了一个我们定义的 my_index 模板。后续还可以对模板进行修改,但是注意只能增加或者删除,无法对已经映射的字段进行更新。
参考资料:
1、Using Logstash to help create an Elasticsearch mapping template
2、Using grok and mutate to type your data
3、Elasticsearch Mapping
4、Grok Filter Plugin
5、Mutate Filter Plugin
6、用logstash导入ES且自定义mapping时踩的坑

用心体验、认真记录,欢迎关注大江小浪的技术人生!